
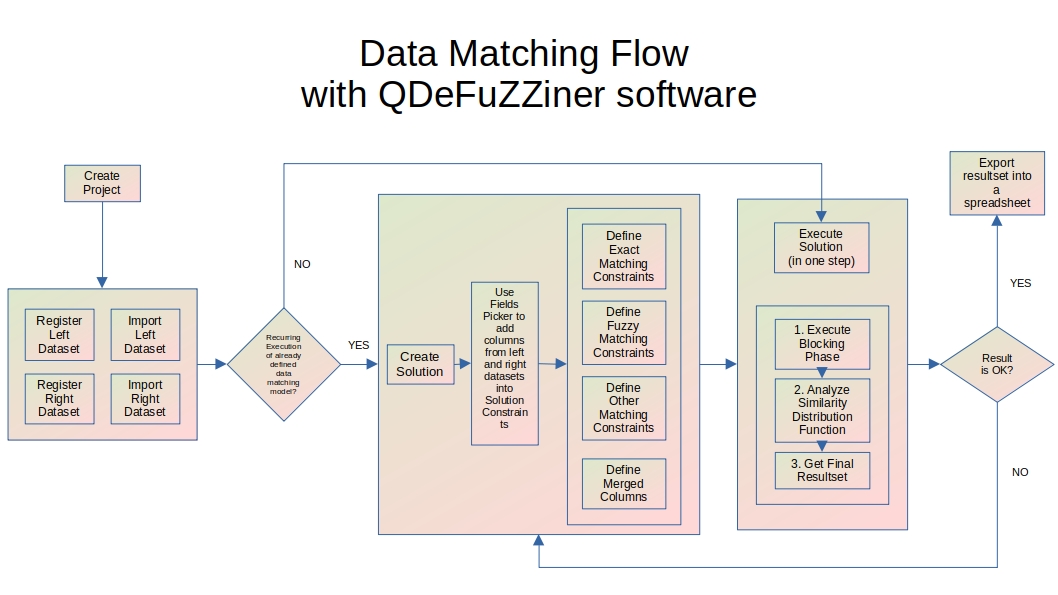
Data Matching Flow with QDeFuZZiner software
In order to be able to use QDeFuZZiner software successfully, we need to understand general flow of a data matching project.
The same general principles apply to a data de-duplication project as well, which differs only in importing the same original input dataset twice, as both left and right dataset, and setting flag "Deduplication (instead of Matching".
Here is the graphical presentation of a typical data matching project:

Description of major phases involved in data matching or de-duplication project:
Project Creation
First step is to create a new project record.
Input Data Importing
Each project is dealing with matching of two input datasets, called "left dataset" and "right dataset", being imported from .csv files.
In this step you need to register both input datasets and then trigger procedure of their import into QDeFuZZiner database, where further data processing will take place.
In case of a data-deduplication project, the same input dataset has to be registered and imported as both left and right dataset.
QDeFuZZiner software imports only .csv files directly, so if you have your input dataset in other formats, such as Excel spreadsheets, you will need first to export them into corresponding .csv files, in UTF-8 format. Fortunately, all spreadsheet softwares has such option of exporting into .csv files. Our recommendation is to use LibreOffice Calc, which has most versatile options for data exporting.
As a good practice, it is recommended that before importing, you do basic preprocessing of input datasets, such as trimming whitespaces, doing proper capitalization (small and big letters), unified formatting of dates etc. Such data preparations will increase quality of fuzzy data matching.
Also, it is advisable to add a column with unique row identifiers, if not already present. It is always recommended, but for data de-duplication it is in fact a must, because you will need to set-up "<>" operator in exact matching constraints for ID columns of left and right dataset.
Solution Creation and Definition (i.e. setting up data matching model)
After input datasets are imported into QDeFuZZiner database, next step is to create a new Solution and define initial data matching model, which we will polish later.
Adding Columns into Data Matching Constraints
By using Fields Picker tool, we need to add column pairs from left and right datasets into applicable sections, for building our data matching model.
Available sections for adding column pairs are: Exact Matching Relations, Fuzzy Matching Relations, Other Constraints and Merged Columns.
After we added data matching constraints into applicable sections, we are ready to fine-tune our model.
Setting Up Exact Matching Constraints
By default, column pairs added to Exact Matching Constraints will have "=" (equal) operator assigned. However, if we are dealing with data de-duplication project, we need to use "<>" (not equal) operator instead, on ID columns from left and right dataset. That is important, because we don't want to compare a row from original dataset with itself (remember that for data de-duplication project we are importing the same original dataset twice, as both left and right dataset).
Setting Up Fuzzy Matching Constraints
In this section, we need to define relative weights for each columns pair. By default, each column pair gets the same relative weight, i.e. the same importance, which is not optimum.
QDeFuZZiner provide two alternative tools for automatic setting-up recommended relative weights. However, these tools are not perfect and you will need to judge it critically and manually adjust relative weights afterwards. Setting-up perfect relative weights is typically matter of trial and error - you will typically experiment with slight variations of the model, until you get satisfactory result.
Setting Up Other Constraints
This section is used to define additional exact matching constraints on individual columns from left or right dataset.
You will use it if you wish to constrain data model to certain custom sub-range, for example to certain town or gender, etc.
Such constraints must be manually defined.
Setting Up Merged Columns
"Merged Columns" is a very powerful, but complex section, with many parameters and options available, which you can use for creation of additional merged columns in final resultset, but also for merge/consolidation of duplicate rows.
It is important to understand that merging is performed not only horizontally (i.e. accross a matching row), but also vertically (i.e. accross all matching rows for the same matched entity). This is especially important in case of deduplication, where thus you can de-duplicate, while preserving data of all duplicate records, through consolidation options. In other words, you can enrich surviving rows from duplicate rows, during de-duplication process.
Solution Execution
After we defined our initial data matching model, we are ready for execution of the model, in order to retrieve resultset.
Typically, it is a cycle of multiple executions, resultset inspections, data model adjustments and fine-tuning, until you get perfect result.
Once data model is optimized, you can use it for repetitive executions of the same data matching model, with fresh imported data. You just need to re-import new data and execute already saved data matching model.
A) Solution Execution in 3 Consecutive Steps
For initial data model adjustments and fine-tunings, you will use this 3-step approach.

Solutions are saved as records of table of solutions, where each record represents a solution, containing definition of parameters and constraints to be applied. Solution execution actually involves two separate sub-phases, which we call "blocking phase" and "detailed fuzzy match phase". Result of the first phase is so-called "solution base table", while result of the second phase is final resultset.
Blocking phase, i.e. creation of solution base table is a time-consuming operation, which, depending on the datasets size and number of columns included into fuzzy match comparison, can take anything from few minutes to few hours to few days to finish! On the contrary, final resultset creation is executed in matter of seconds or minutes. Therefore, there is much sense to follow this recommended three-step approach: you first define solution parameters and constraints, then create solution base table (blocking phase), then open similarity distribution tool to visually determine area of optimum threshold values, then consecutively vary threshold values (inside previously determined optimum range) and execute detailed fuzzy match phase until getting satisfactory results.
1. Execute Blocking Phase
"Blocking" phase is phase in which a subset of best matching candidate record pairs are chosen from the whole universe of all possible combinations.

Blocking phase is actually sequence of two distinct consecutive sub-phases:
a) Sub-phase of rough similarity filtration (blocking)
By using rough filtration on similarity, best candidates (those matching pairs which have string similarity greater than blocking similarity limit) are passed-through and saved into an intermediate table called "solution base table".
b) Detailed similarity calculation
After best candidates are saved, then detailed similarity calculation takes place for each passed-through record pair.
The most important parameter we need to define for blocking phase is called "blocking similarity limit". This value represents a similarity threshold that is used in so-called "blocking phase". Term "blocking" is used here to designate phase in which Cartesian product of all possible combinations of records from left and right dataset is constrained, i.e. narrowed down to a much smaller subset of combinations, according to some blocking similarity criteria. This is very important sub-phase, because for medium and big datasets, detailed fuzzy match calculation would become infeasible (extremely time consuming), if we would compare and analyze all possible combinations in detailed similarity calculation sub-phase.
The bigger is the blocking similarity limit value, the less number of record pairs will be saved in the solution table and consequently next phase (detailed fuzzy match phase) will be faster. However, if the blocking similarity values is too big, we risk to omit true matches.
When a solution definition is executed, QDeFuZZiner creates a table for a solution, which we call "solution base table". This table is constructed as combination of records from left and right datasets, according to exact and fuzzy matching constraints and blocking similarity limit. Solution base table thus contains subset of left and right dataset records combinations, which satisfy condition of blocking similarity limit. Only combinations saved into the solution table are then analyzed in the detailed fuzzy match sub-phase.
Besides blocking similarity limit, parameter "Use dictionaries (yes/no)" also influences on the solution base table creation. If dictionary is used, strings used for blocking and detailed phase are lexemized into lexems, according to selected dictionary. Lexems are then used for similarity calculation instead of original words. This can be useful in cases of big strings, such as verbose product descriptions, because lexemization decreases variations in related words.

Of course, exact and fuzzy match constraints also influence blocking phase. Adding exact matching constraints can dramatically reduce time for execution of blocking phase and also improve accuracy of fuzzy matching model.
Immediately after rough filtration of candidate record pairs, detailed calculation of string similarity is executed on the passed-through records.
Overall result of the blocking phase is intermediary table stored in the database, called "solution base table", which contains record-pairs with calculated string similarity values.
2. Analyze Similarity Function Distribution
After blocking phase is executed and solution base table is saved in the database, we can investigate similarity function distribution visually, in order to determine appropriate similarity threshold to discern matches from non-matches. QDeFuZZiner provide and advanced tool for similarity function distribution graphical representation, along with mathematical functions trying to provide a clue what would be the optimal threshold.

3. Get Final Resultset
In this phase, value of the "similarity threshold" parameter is used to discern between matches and non-matches. Result of this detailed fuzzy match phase is creation and saving of a resultset table which is then loaded into the datagrid, from which it can be exported into a spreadsheet or flat file.
Besides similarity threshold, this phase is also influenced by exact and fuzzy matching constraints. It is also influenced by the "Join Type" and "Return only best matching record (yes/no)" parameters.

B) Solution Execution in 1 Step
Execution in one step is suitable for re-running a solution on updated (re-imported) input datasets, when you expect that new imported data will not substantially change already defined data matching model.

Resultset Exporting
After a solution is executed, resultset will be saved as a new table in the database and will be presented in a datgrid, from which we can filter, sort, search and export results into a spreadsheet.

Further Reading
Introduction To Fuzzy Data Matching
Managing QDeFuZZiner Projects
Importing Input Datasets into QDeFuZZiner
Managing QDeFuZZiner Solutions
Demo Fuzzy Match Projects
Various Articles on QDeFuZZiner
Our Data Matching Services
Do you wish us to perform fuzzy data matching, de-duplication or cleansing of your datasets?
Check-out our data matching service here: Data Matching Service