
What is QDeFuZZiner Solution?
By term "Solution" we consider section of the QDeFuZZiner in which fuzzy matching specification is defined, fuzzy matching execution is performed and results are acquired and manipulated. Solution is the most important object in QDeFuZZiner software.
A solution is an entity on which you define all the parameters that will influence how fuzzy matching will be performed, provide specification of field pairs to be matched, along with exact, fuzzy and other constraints.
By executing solution specification, fuzzy data matching analysis is executed on the underlying PostgreSQL database. Upon completion of fuzzy matching, retrieved results are saved as new table and presented in a datagrid.
Retrieved resultset can be exported into a spreadsheet (.xlsx, .xls, .ods) or flat plain text (.csv, .tab, .txt) files.
Each solution belongs to a certain project, i.e. one project can contain multiple solutions.
Solution Architecture (Underlying logic, workflow and database tables)
In order to understand how to set-up a solution, we need to understand basics of internal fuzzy match architecture and workflow.
Solutions are saved as records of table of solutions, where each record represents a solution, containing definition of parameters and constraints to be applied. Solution execution actually involves two separate phases, which we call "blocking phase" and "final resultset retrieval phase". Result of the first phase is so-called "solution base table", while result of the second phase is final resultset.
These two phases can be executed in one step or in two (or three) consecutive distinctive steps, by using corresponding buttons.
Screenshot from versions before v. 1.2.0:

Screenshot from version v. 1.2.0:

We recommend execution in two (or three) distinctive steps:
- Execute Blocking Phase (i.e. Prepare and execute Solution Base Table SQL Query) ---> solution base table creation
- Analyze Similarity Function Distribution (i.e. Open Similarity Distribution Estimator) (optinally) ---> visually assessing optimum similarity threshold value
- Get Final Resultset (i.e. Prepare and execute Result SQL Query) ----> resultset table creation and representation in datagrid
Blocking phase, i.e. creation of solution base table is a time-consuming operation, which, depending on the datasets size and number of columns included into fuzzy match comparison, can take anything from few minutes to few hours to few days to finish! On the contrary, final reultset retrieval phase is executed in matter of seconds or minutes. Therefore, there is much sense to follow this recommended three-step approach: you first define solution parameters and constraints, then create solution base table (blocking phase), then open similarity distribution tool to visually determine area of optimum threshold values, then consecutively vary threshold values (inside previously determined optimum range) until getting satisfactory results.
Execution in one step is suitable for re-running a solution on update (re-imported) input datasets, when you expect that new imported data will not substantially change already defined data matching model.
Blocking Phase
"Blocking" phase is phase in which a subset of best matching candidate record pairs are chosen from the whole universe of all possible combinations.
Blocking phase is actually sequence of two distinct consecutive sub-phases:
1. Sub-phase of rough similarity filtration (blocking)
By using rough filtration on similarity, best candidates (those matching pairs which have string similarity greater than blocking similarity limit) are passed-through and saved into an intermediate table called "solution base table".
2. Detailed similarity calculation
After best candidates are saved, then detailed similarity calculation takes place for each passed-through record pair.
The most important parameter we need to define for blocking phase is called "blocking similarity limit". This value represents a similarity threshold that is used in so-called "blocking phase". Term "blocking" is used here to designate phase in which Cartesian product of all possible combinations of records from left and right dataset is constrained, i.e. narrowed down to a much smaller subset of combinations, according to some blocking similarity criteria. This is very important sub-phase, because for medium and big datasets, detailed fuzzy match calculation would become infeasible (extremely time consuming) if we would compare and analyze all possible combinations in detailed similarity calculation sub-phase.
The following screenshot shows parameters related to blocking phase:

The bigger is the blocking similarity limit value, the less number of record pairs will be saved in the solution table and consequently next phase (detailed fuzzy match phase) will be faster. However, if the blocking similarity values is too big, we risk to omit true matches.

When a solution definition is executed, QDeFuZZiner creates a table for a solution, which we call "solution base table". This table is constructed as combination of records from left and right datasets, according to exact and fuzzy matching constraints and blocking similarity limit. Solution base table thus contains subset of left and right dataset records combinations, which satisfy condition of blocking similarity limit. Only combinations saved into the solution table are then analyzed in the detailed fuzzy match sub-phase and similarity values calculated for them.
Besides blocking similarity limit, parameter "Use dictionaries (yes/no)" also influences on the solution base table creation. If dictionary is used, strings used for blocking and detailed phase are lexemized into lexems, according to selected dictionary. Lexems are then used for similarity calculation instead of original words. This can be useful in cases of big strings, such as verbose product descriptions, because lexemization decreases variations in related words.

Of course, exact and fuzzy match constraints also influence blocking phase. Adding exact matching constraints can dramatically reduce time for execution of blocking phase and also improve accuracy of fuzzy matching model.
Immediately after rough filtration of candidate record pairs, detailed calculation of string similarity is executed on the passed-through records.
Overall result of the blocking phase is intermediary table stored in the database, called "solution base table", which contains record pairs with calculated string similarity values.
By using similarity distribution estimator tool, we can then visually assess optimum threshold to be used in resultset retrieval phase.

Resultset Retrieval Phase
Following screenshot shows parameters important for final resultset retrieval phase:

In this phase, value of the "similarity threshold" parameter is used to discern between matches and non-matches. Result of this phase is creation and saving of a resultset table which is then loaded into the datagrid, from which it can be exported into a spreadsheet or flat file.

Besides similarity threshold, this phase is also influenced by exact and fuzzy matching constraints. It is also influenced by the "Join Type" and "Return only best matching record (yes/no)" parameters.

Major Elements of a QDeFuZZiner Solutions Page
If you select a project in the Projects page and then click on the "Records Matching Analysis" tab, Solutions page will be shown.

Solutions Datagrid (Add, Edit and Browse Solutions)
You will notice that the upper part of the Solutions page contains a datagrid through which you can add, edit and navigate solutions.

For adding new solutions, editing existing solutions and browsing through solutions, you can use datagrid navigator toolbox.

Additionally, there is possibility to clone, i.e. copy whole solution definition into another solution. This can save you considerable amount of time - instead of creating new solution from scratch, copy an existing solution and then change parameters that you wish to vary. Typically, you will create multiple solutions for the same project, exploring how various parameters influence result, in persuit of optimum set of parameters.
Screenshot from version before v. 1.2.0:

Screenshot from version v. 1.2.0:

The datagrid section also contains buttons used for execution of a fuzzy match solution, in order to retrieve resultset. You can execute solution in one step, by using "EXECUTE SOLUTION" button, or in two or three distinct, consecutive steps, by using other buttons.
Screenshot from version before v. 1.2.0:

Screenshot from version v. 1.2.0:

Solution Sub-Pages
Lower part of the Solutions page consists of multiple sub-pages (tabs) for various elements of a solution. By default, "Solution Definition / Solution Parameters / Parameters" sub-page is opened.
Solution Definition
Solution Parameters
Solution parameters tab contains three sections: solution general section, solution blocking phase parameters, solution detailed fuzzy match phase section.
Screenshot from version before v. 1.2.0:

Screenshot from version v. 1.2.0:

Solution Parameters - Blocking Phase Parameters
In the central section, there are parameters relevant for blocking phase.

Blocking similarity limit value is threshold used for discriminating between records combinations that will be saved into the solution table and those record pairs that will be ingored, i.e excluded from the solution table.
If we check "Use Dictionaries" and select a dictionary, then QDeFuZZiner will use lexemization to convert original words into lexems, which are then used for similaririty calculation instead of original words. This can be useful for verbose, big strings, such as long descriptions.
Solution Parameters - TF-IDF Post-processing Options
Starting from the version 1.1.0, TF-IDF algorithm is added as post-processing option. TF-IDF (term frequency–inverse document frequency) is an algorithm which gives more importance to non-frequent words and less importance to frequent words.
This option switched-on can dramatically increase matching quality for projects where e.g. two list of companies have to be matched.

You can select one column pair to be post-processed by this algorithm, by picking left and right dataset columns.
You can also switch-on "CleanCompany" algorithm, which will eliminate company type abbreviations and thus improve matching of company names even more.
Solution Parameters - Resultset Retrieval Phase
In this, right positioned section, there are parameters relevant for the final resultset retrieval phase.

Parameter "Deduplication (instead of Matching)" (i.e. "It is deduplicate type (instead of record linkage type) solution (yes/no)" in older versions), determines whether the solution is record linkage or data deduplication solution. If this option is unchecked (default), meaning record linkage, then resultset will contain records matched combination of records from left and right dataset satisfying the criterial of parameters. If this parameter is checked, meaning de-duplication, then resultset will contain de-duplicated records from original left dataset which satisfy criteria!
"Similarity Threshold" parameter is used to discern between matches and non-matches, based on calculated string similarity values, being calculated in previous blocking phase.
"Join Type" parameter determines how records from left dataset, solution base table and right dataset will be combined together into final resultset table. if using inner join type, record pairs having corresponding records present in all three tables will be passed to resultset table.
If using left outer join, all records from left dataset will be present and only matching records from right dataset. If using right outer join, all records from right dataset and only matching records from left dataset will be retrieved.
"Return only best matching records" additionaly determines whether all matching combinations or only best matching combinations will be retrieved, in case of left and right joins. In case of inner join, it has no influence at the moment.


Note: In version v. 1.2.0 we introduced data validation logic which automatically sets Join Type to "left outer join" and switches on option "Return Only Best Matching Records?" if you switch-on option "Deduplication (instead of Matching)". This was introduced to prevent wrong options, i.e. options which don't make sense for de-duplication.
Solution Fields Picker
In the solution fields picker, columns (i.e fields) from both left and right datasets are listed. By selecting records in left and right datasets and then clicking on one of the buttons below, we can add pield pairs or fields into corresponding solution constraints (exact matching constraints, fuzzy matching constraints, other constraints, merged columns).

Solution Constraints
In the solution constraints section we have separate sub-tabs for each type of constraints, that we incuded into solution definition using Fields Picker described above.
Exact Match Constraints
Exact matching relations are constraints based on exact matching (operator of equality "=") or exact non-matching (operator of inequality "<>"). Depending on the content of your datasets, if you are able to meaningfully set exact matching constraints, definitely do it, because exact matching constraints greatly enhance fuzzy matching quality and decrease execution time!
If you are performing identification of duplicate records or perform deduplication solution, then you MUST include at least one exact match constraint with unique identity fields (typicall an "ID" or "id" field) for left and right dataset, and exact not-matching ("<>") relation! That is required to exclude comparing each record with itself! Here is an example of a such definition, where we have "<" operator on IDs and some other custom exact matching constraints, in order to improve accuracy and descrease execution time.


Fuzzy Match Constraints
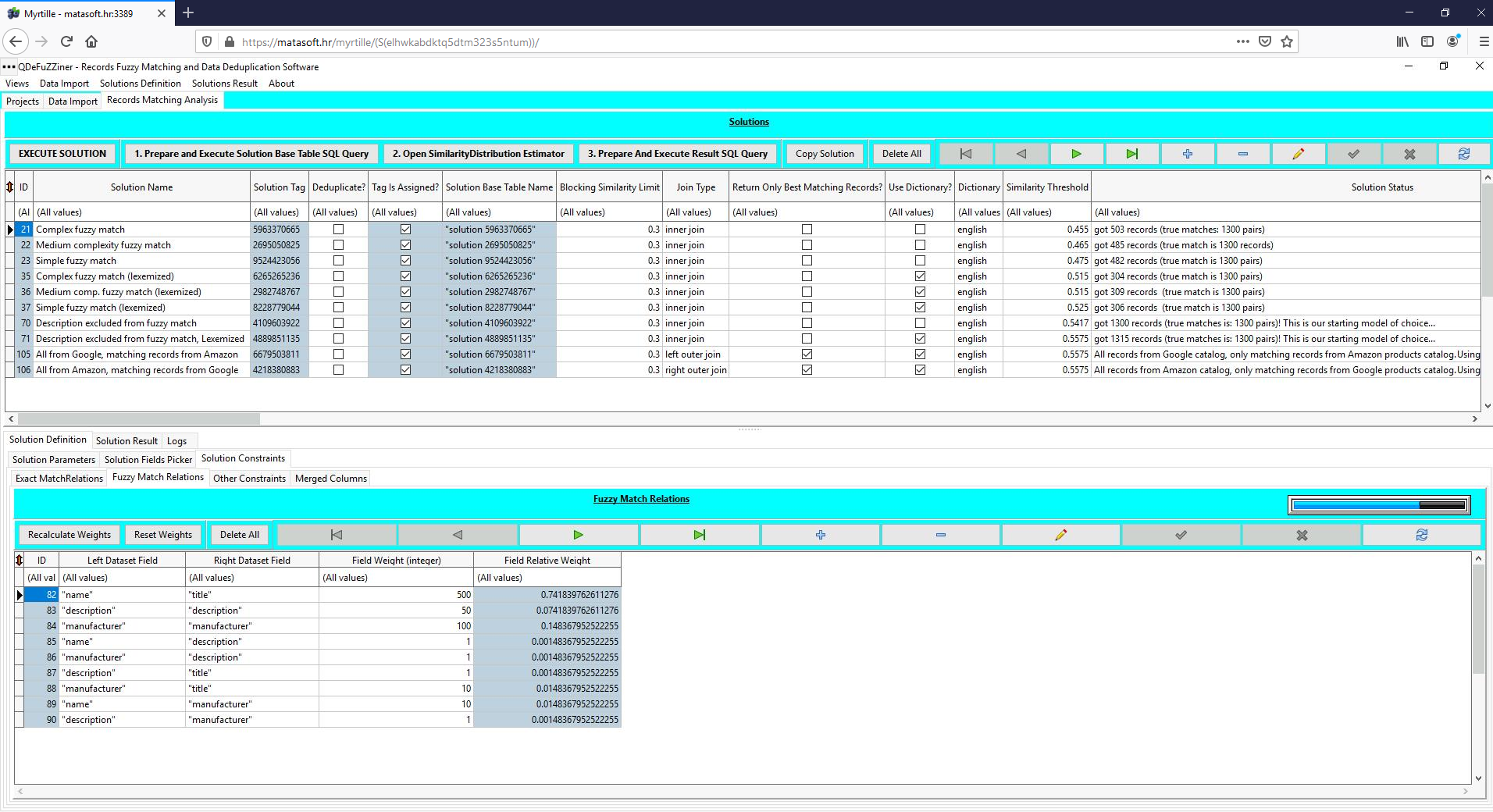
We might say that definition of fuzzy matching constraints is very heart of each fuzzy match solution. For each included fields pair, we can define integer value for Field Weight. QDeFuZZiner will take care of calculating relative weight. Sum of all relative weights is 1.


Other Constraints
You will occasionally want to additionaly constrain solution to a subset of original data. You can do it on fields belonging to left or right, by using the other constraints functionality.

Merged Columns List
You can define merged columns to be included in resultset. Merged column is a combination of values from left and right dataset fields being matched, which can be either included into the resultset as new column, either can be used for updating existing original column with aggregated (i.e. merged) value.

First parameter which influence how merging will be performed is parameter "Merging Type".
QDeFuZZiner provides several merging types:
- "greatest" (biggest text will be used)
- "least" (smallest text will be used)
- "concatenated" (texts will be concatenated togethe, separated by space
- "piped" (texts will be concatenated together, separated by "|" character
- "words" (list of words extracted from both fields)
- "lexemized" (list of lexemized words extracted from both fields)

In recent QDeFuZZiner versions, merging and consolidation feature has been substantially improved on both backend and frontend side. On the backend side, merging and consolidation is now performed not only horizontally (i.e. accross a matching row), but also vertically (i.e. accross all matching rows for the same matched entity). This is especially important in case of deduplication, where now you can easily de-duplicate, while preserving data of all duplicate records, through consolidation options. In other words, you can enrich surviving rows from duplicate rows, during de-duplication process.
Another important enhancement is that merged columns can be now used to provide values for updating original columns in left or right dataset. Thus us controled by several parameters: "Update Left Field", "Update Right Field", "Update Source", "Update Rule".
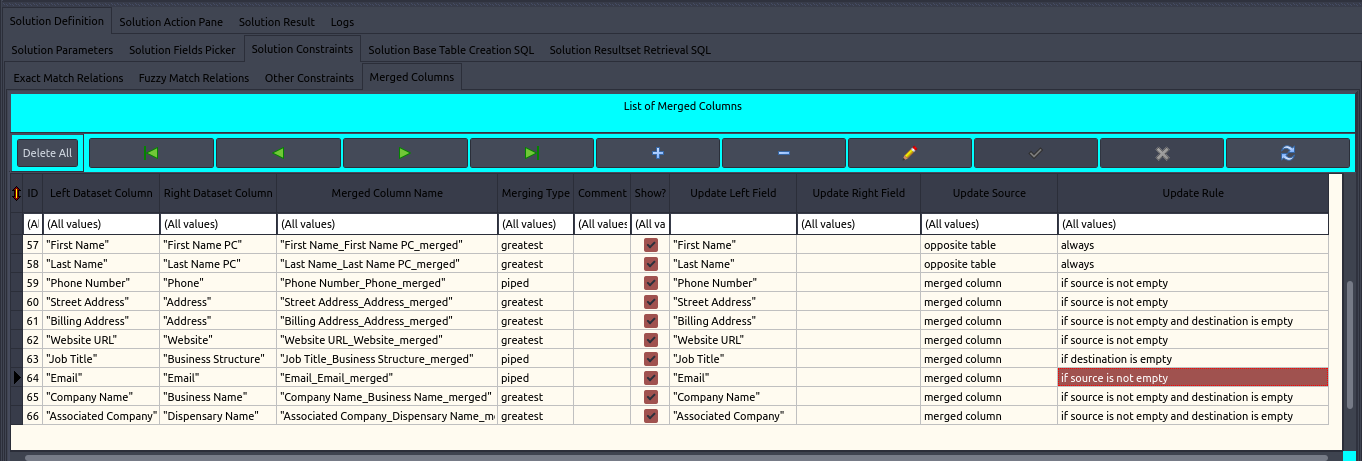
Option "Show" defines whether a merged/consolidated column will be presented in resultset or not. If not, it means that it is used only for calculating values to be used for updating original columns in left or right dataset.
If "Update Left Field" and "Update Right Field" are defined (i.e. not empty), then defined original columns in left or right dataset will be updated from "source", where source can be either merged column value or from corresponding column in the opposite table.
"Update Source" parameter defines whether columns to be updated will be updated from merged column value or directly from opposite original table. Opposite table means that the left dataset will be updated from right dataset and vice versa.

"Update Rule" parameter defines in which circumstances update (update of original left or right column) with value from source (from merged column value or from oposite table column) will be applied. Possible choices are:
- always
- is source is not empty
- if source is empty
- if source is not empty and destiantion is empty
- if source is empty and destination is not empty
- if destination is empty
- if destination is not empty

In version v. 1.2.0, Merged Columns feature has been additionally improved to enable massive update of merging options to the whole list of merged columns.





Solution Result
Upon execution of a solution, solution resultset table is created in the underlying database and data is loaded into resultset datagrid, in a seoarate form. Resultset can be searched, filtered, sorted and exported to various formats.

Besides being loaded upon solution execution, solution resultset can also be loaded afterwards, any time you wish. You can load and manipulate previously saved resultset table in the "Solution Result" sub-page.





Logs
This sub-page provide information on progress of a solution being currently executed.
Further Reading
Introduction To Fuzzy Data Matching
Data Matching Flow
Managing QDeFuZZiner Projects
Importing Input Datasets into QDeFuZZiner
Managing QDeFuZZiner Solutions
Demo Fuzzy Match Projects
Various Articles on QDeFuZZiner
Our Data Matching Services
Do you wish us to perform fuzzy data matching, de-duplication or cleansing of your datasets?
Check-out our data matching service here: Data Matching Service