
Matching Task
This was a real-life task to match master list containing information about employee name, company and employee title, with a lookup list containing other information such as email, phone and address, besides these columns.
The task was to enrich the master dataset with email, phone and address information from the lookup dataset.
Input Datasets Importing
As always, the first step was to register master dataset as the left dataset and lookup dataset as the right dataset.


By clicking "Import both input files to server" button, datasets were imported into the underlying PostgreSQL database.
Fuzzy Match Model
Next step was to create new solution and define appropriate parameters and fuzzy data matching model.
After little bit of experimentation, I got a good fuzzy data matching model, with following parameters:

Blocking similarity of b=0.45 was optimum for rough pre-matching of these two datasets (so-called "blocking" phase).

Final similarity threshold of t=0.69 was optimum for discerning matches from non-matches in this model.
We were using left join with option of retrieving only best matches. That's because we want to retrieve all rows from master (left dataset) and only best matched rows from lookup dataset (right dataset).

Additionally, it was useful to utilize TFIDF post-processing on company names.

The fuzzy data matching model was based on 3 column pairs (employee name, title and company name), with very high relative weight given to person name. But, don't forget that we are also utilizing TFIDF post-processing on company name, so importance given to company name is in reality much greater than somebody might conclude from fuzzy matching constraints tab only.
Blocking was performed on employee name column only.


We have also provided definition of merged columns for email, phone and address, in two variants. First variant is for updating original empty columns in the master dataset (left dataset) from the best matched row from lookup dataset, while the second variant is to provide additional merged columns with individual values being concatenated by pipe symbol (" | "). The latter is to ensure that we will pick up all emails, phones and addresses if there are multiple matches from the lookup dataset for one row in the master dataset.


As always, we can use 3-step or 1-step approach to execute the solution.


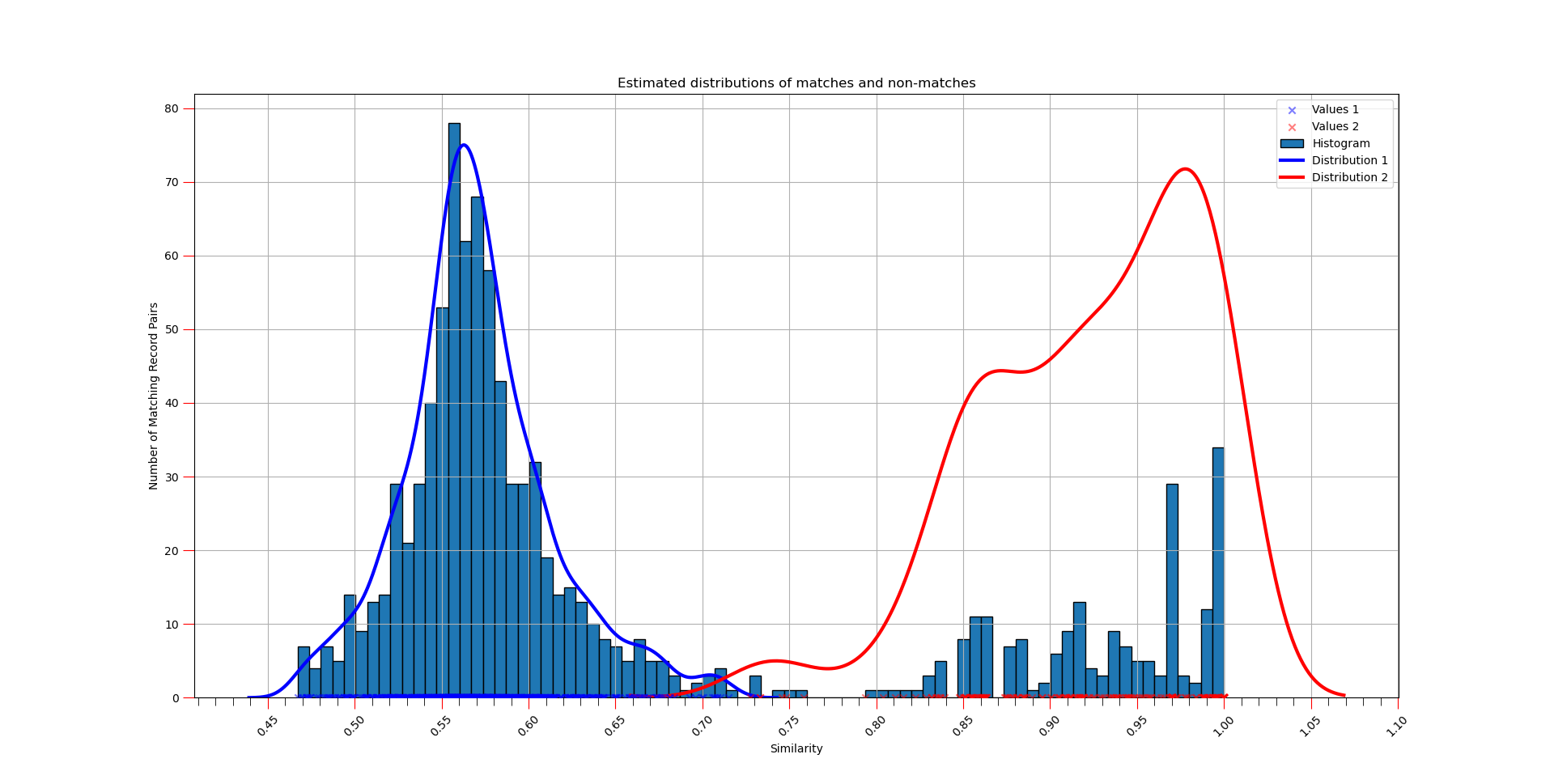
Similarity Distribution Chart
We got pretty good separation of matches and non-matches with this data matching mode, which is clearly demonstrated by the distribution chart.

file:///home/zlatko/Preuzimanja/ICMG%20&%20Medicairian%20Contacts/Figure_2.png
Matching Result
By executing this fuzzy data matching model, we got very good and straight-forward results.

Further Reading
Introduction To Fuzzy Data Matching
Data Matching Flow
Managing QDeFuZZiner Projects
Importing Input Datasets into QDeFuZZiner
Managing QDeFuZZiner Solutions
Demo Fuzzy Match Projects
Various Articles on QDeFuZZiner
Our Data Matching Services
Do you wish us to perform fuzzy data matching, de-duplication or cleansing of your datasets?
Check-out our data matching service here: Data Matching Service