
Project
There are 2614 records in the DBLP dataset and 2295 records in the ACM dataset. We need to match bibliographic records from the two datasets.
It is known that there are 2225 true matching pairs.
Fortunately, we can set exact matching constraint on "year" field, which greatly improves accuracy and speed of execution.

Input Datasets Import
Left Dataset Schema Definition
DBLP bibliographic database is an Excel file containing 2614 records. It has been registered as "left dataset" for fuzzy matching. Upon registering file, it has been automatically converted into a .tab format text file and then imported into the underlying Postgresql database.

Right Dataset Schema Definition
ACM bibliographic database is an Excel file containing 2295 records. It has been registered as "right dataset" for fuzzy matching. Upon registering file, it has been automatically converted into a .tab format text file and then imported into the underlying Postgresql database.

Fuzzy Data Matching Solution
Identify Related Records
In this example we were able to set parameters in such way that we can clearly separate matches from non-matches. Open similarity distribution estimator (button "2. Open SimilarityDistribution Estimator" and check visually how distribution of similarity clearly separates non-matches and matches. This however is not always possible to achieve.
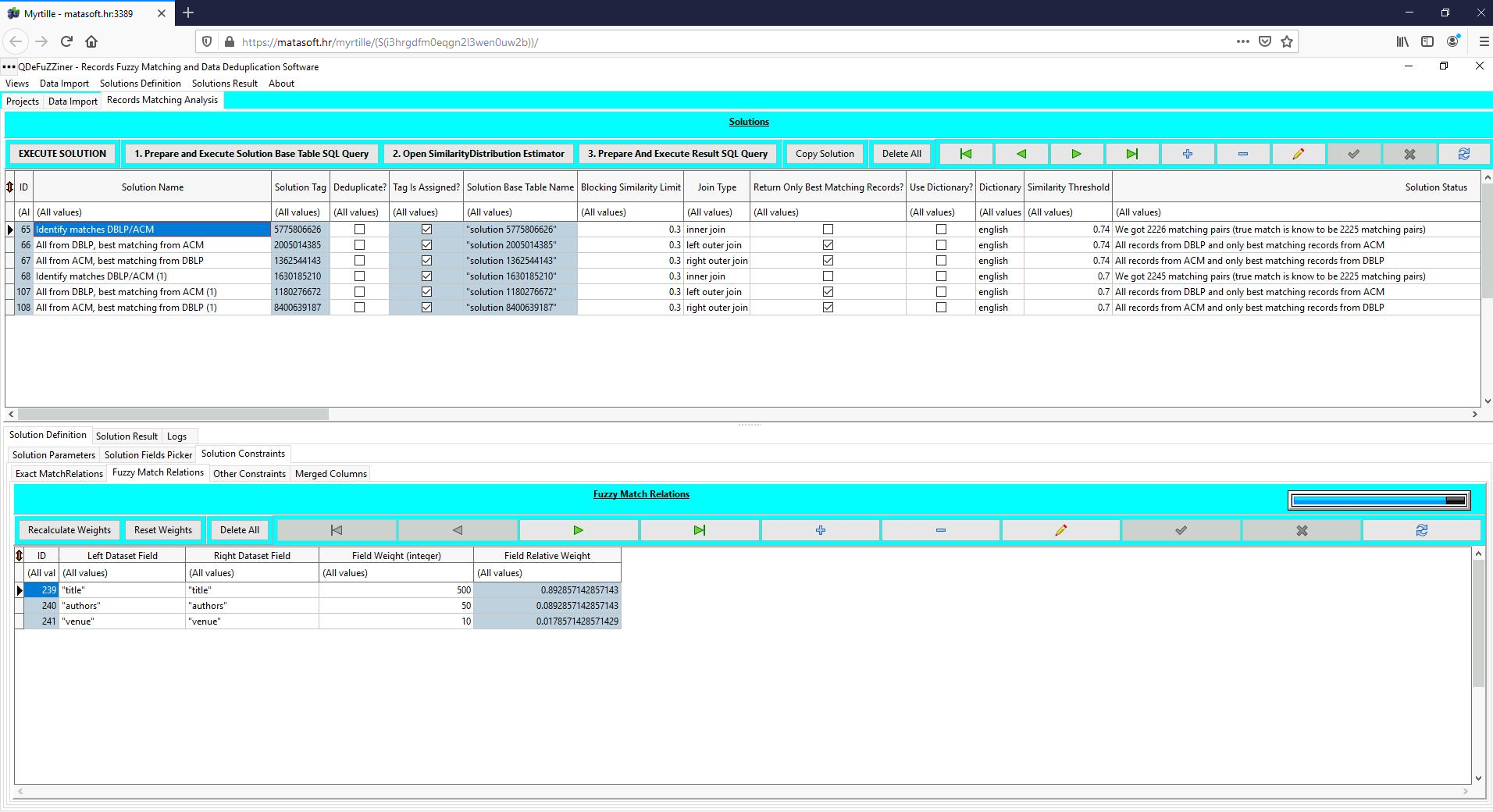
Under Solution Constraints check how we defined both fuzzy matching constraints (on "titles", "venue" and "authors") and exact matching constraint on "year" field. Whenever you can define an exact constraint on a fields pair, definitely do it - in most cases it will dramatically improve accuracy and speed of execution.


Under Solution Constraints / Exact Match Relations sub-tab, we were able to specify exact matching condition on the year fields from the two datasets. Establishing an exact constraint greatly improves accuracy and speed of execution. Prerequisite for setting such constraints is that both datasets contain complete information in that field (no empty cells), and that the information is guaranteed to be in same format and without typos.

Of course, we also defined additional fuzzy matching constraints, in the Solution Constraints / Fuzzy Match Relations sub-tab.

You can check distribution of non-matches and matches for this particular solution, by clicking the button "Open Similarity Distribution Estimator". This is an example of a very-well separated of matches and non-matches, thus assessing of optimum threshold value was straight-forward!


Link and Merge Two Bibliographic Databases
Once we have found satisfactory parameters for identifying related records in two datasets, we copied the solution into a new solution and adjusted parameters to retrieve all records from the DBLM dataset and only related records from the ACM dataset.




We have also defined merged columns, with various types of merging.

Fuzzy Match Result
A solution can be executed in one or several consecutive steps, by using appropriate buttons.

After a solution has already been executed and resultset is saved, you can open the resultset anytime, by using one of corresponding buttons, in the "Solution Result" sub-tab.

