Project
This is example of a pretty complex and hard fuzzy matching task, due to relatively big dataset, multiple columns to be matched and inability to define an exact matching constraints.
There are 64264 records in "Scholar" dataset and 2617 records in "DBLP" dataset. Task is to match records from two biobiliographic lists. It is known that there are 5348 true matching pairs.
Number of possible combinations is pretty big (cartesian product), so in this project we had to pay attention on blocking similarity limit value, in order to constrain number of combinations to be passed into detailed fuzzy match comparison. If blocking similarity limit is too low, time execution will be very long. If the value is to high, we might miss some matches.
Unfortunately, since data in "year" column is sparse, unlike in DBLP/ACM project (see https://matasoft.hr/QTrendControl/index.php/qdefuzziner-fuzzy-data-matching-software/demo-fuzzy-match-projects/36-record-linkage-example-link-dblp-and-acm-bibliographic-databases), here we cannot utilize exact matching constraint, but must rely solely on fuzzy matching constraints. This reflects in much longer time of execution.

Similarities and Difference with "DBLP"/"ACM" Project
As we already pointed out, this project is similar to "DBLP"/"ACM" project (see https://matasoft.hr/QTrendControl/index.php/qdefuzziner-fuzzy-data-matching-software/demo-fuzzy-match-projects/36-record-linkage-example-link-dblp-and-acm-bibliographic-databases).
However, unlike DBLP/ACM project, where we were able to define an exact matching constraint, that increased both accuracy and speed of execution, in the DBLP/Scholar project we cannot use such exact matching constraints, because data in "year" column is sparse, i.e. there are empty cells. When data is sparse, i.e. information is incomplete or not formatted in the same way, we cannot enforce exact matching constraint and therefore must rely on fuzzy matching constraints only. As a consequence, execution time is increased and fuzzy matching quality might suffer as well.
Let's compare execution times in both cases. (Beware, though, that size of Scholar dataset also adds to the increased execution time.)
We can see that in DBLP/ACM execution time was 2 minutes and 18 seconds, while in case of DBLP/Scholar it was 47 minutes and 50 seconds!
DPLP/ACM Execution Times (with exact matching constraint)

DBLP/Scholar Execution Times (without exact matching constraints)

Input Datasets Import
Left Dataset Schema Definition
"Scholar" dataset is an Excel file containing 64264 records. It has been registered and imported as "left" dataset for fuzzy matching. During the file registration, it has been converted to a .tab format text file and imported into the PostgreSQL database afterwards.

Right Dataset Schema Definition
"DBLP1" dataset is an Excel file containing 2617 records. It has been registered and imported as "right" dataset for fuzzy matching. During the file registration, it has been converted to a .tab format text file and imported into the PostgreSQL database afterwards.

Fuzzy Data Matching Solution
Identify Matching Records from Two Datasets
In this solution, we were able to set parameters in such way that we can clearly separate matches from non-matches. Open similarity distribution estimator (button "2. Open Similarity Distribution Estimator" and check visually how distribution of similarity clearly separates non-matches and matches. This however is not always possible to achieve.
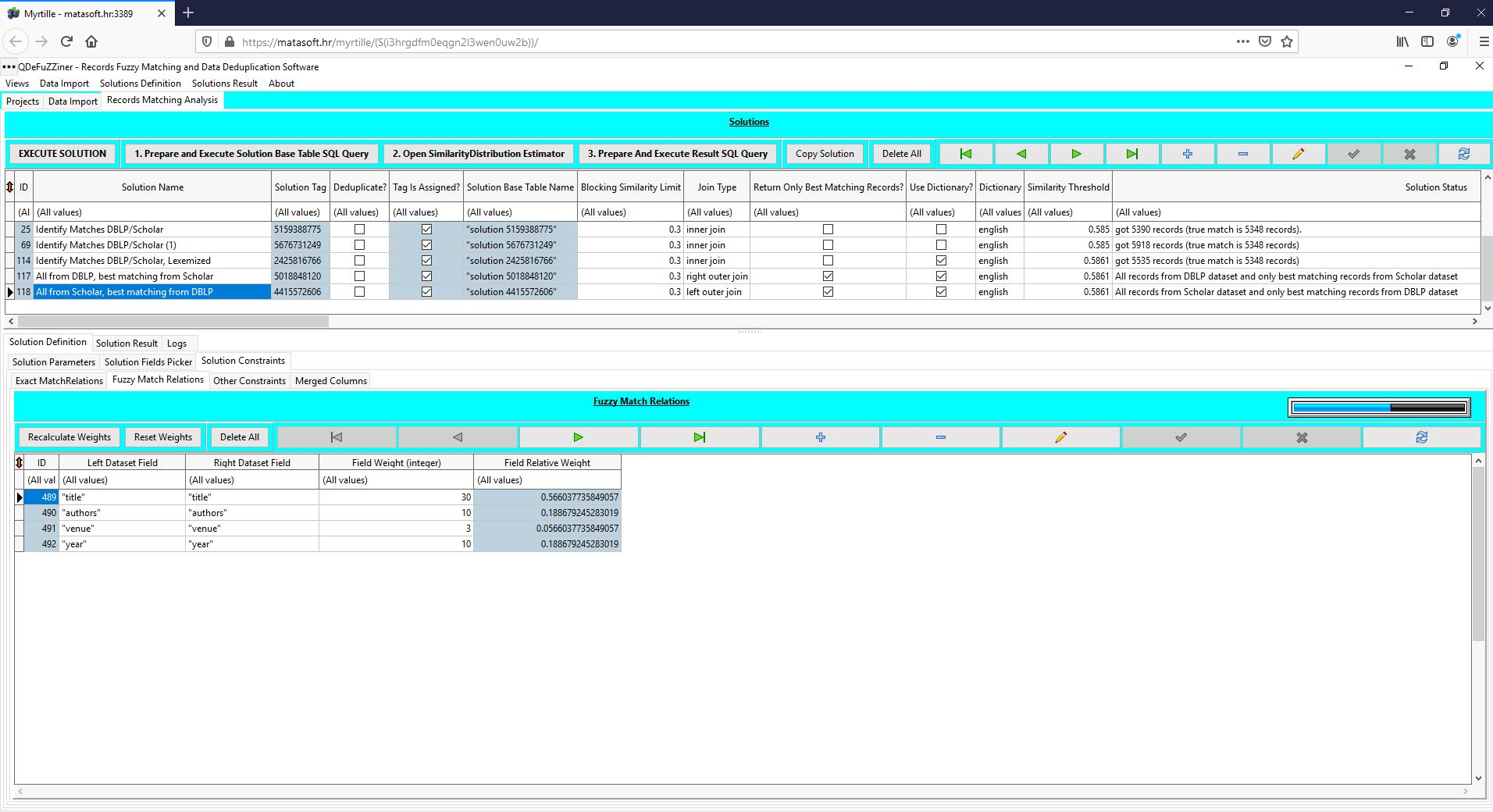
Under Solution Constraints check how we defined fuzzy matching constraints (on "titles", "venue", "authors" and "year"). Unfortunately, we couldn't define exact matching constraint on "year" field because of incomplete (sparse) data. Whenever you can define an exact constraint on a fields pair, definitely do it - it will dramatically improve accuracy and speed of execution. However, in this project we are, unfortunately, unable to provide any exact matching constraint.
Lexemization (using dictionaries) seems to improve quality of fuzzy matching, though substantially increasing execution time.
Note that we have chosen threshold that retrieves little bit more records than known 5348 records. That's because we assume that there are more than one record pairs retrieved for some records from left dataset.



You can check distribution of matches and non-matches, by clicking the button "Open Similarity Distribution Estimator". This visual tool can help you to determine range for searching optimum threshold value.


Link and Merge Two Bibliographic Databases
After we have determined satisfactory parameters for identifying related records from two datasets, we copied the project into a new project, and subsequently adjusted parameters to return all records from the "Scholar" dataset and only best matching records from the "DBLP" dataset.
Pay attention to the "left outer join" and "return only best matching" parameters switched on!



We have also defined merged column, with various types of merging.

Fuzzy Match Result
A solution can be executed in one or several steps, by using corresponding command buttons.

Once a solution has been executed and resultset is saved in the database, you can open resultset anytime, by clicking on corresponding buttons in the "Solution Result" sub-tab.


Further Reading
Introduction To Fuzzy Data Matching
Data Matching Flow
Managing QDeFuZZiner Projects
Importing Input Datasets into QDeFuZZiner
Managing QDeFuZZiner Solutions
Demo Fuzzy Match Projects
Various Articles on QDeFuZZiner
Our Data Matching Services
Do you wish us to perform fuzzy data matching, de-duplication or cleansing of your datasets?
Check-out our data matching service here: Data Matching Service